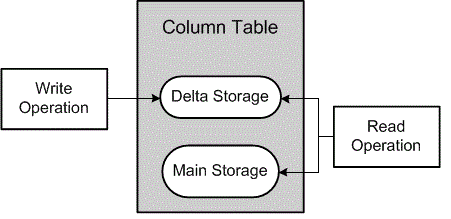
HANA is a hybrid database which uses both row as well as column store techniques. Column store table stores records in a sequence of columns . A column store table is comprised of two index types, for each column a main index and a delta index. The delta storage is optimized for write operations and the main storage is optimized in terms of read performance and memory consumption.
Conventional databases i.e. row store are good for write operations therefore database with row store architecture is also called as write optimized system. This type of architecture is effective especially in OLTP systems.
On the other hand, system which are used for ad hoc querying with huge volume of data are read optimized, i.e. analytical or data warehouse systems where data is mostly used for reporting purpose. These systems represents read optimized in which bulk amount of data load is performed with ad hoc queries. Other examples of read optimized systems are CRM (Customer Relationship Management), Electronic Library catalogues and other ad hoc inquiry systems. In such environments, a column store architecture, in which the values for each single column are stored contiguously, should be more efficient.
Conventional databases i.e. row store are good for write operations therefore database with row store architecture is also called as write optimized system. This type of architecture is effective especially in OLTP systems.
On the other hand, system which are used for ad hoc querying with huge volume of data are read optimized, i.e. analytical or data warehouse systems where data is mostly used for reporting purpose. These systems represents read optimized in which bulk amount of data load is performed with ad hoc queries. Other examples of read optimized systems are CRM (Customer Relationship Management), Electronic Library catalogues and other ad hoc inquiry systems. In such environments, a column store architecture, in which the values for each single column are stored contiguously, should be more efficient.
Example: create history column table A.
CREATE HISTORY COLUMN TABLE A(c NVARCHAR(1000)) PARTITION BY ROUNDROBIN PARTITIONS 2;
SQL For Monitoring Column Store Table:
To get a high-level overview of the amount of memory used for Column Store tables, you can execute the following SQL statement:
SELECT ROUND(SUM(MEMORY_SIZE_IN_TOTAL)/1024/1024) AS "CS Memory (MB)",
ROUND(SUM(MEMORY_SIZE_IN_MAIN)/1024/1024) AS "CS Memory In Main (MB)",
ROUND(SUM(MEMORY_SIZE_IN_DELTA)/1024/1024) AS "CS Memory In Delta(MB)"
FROM M_CS_TABLES WHERE LOADED <> 'NO’
To get a breakdown by host, service, and schema, you can execute the following statement:
SELECT S.HOST AS "Host",
SERVICE_NAME AS "Service",
SCHEMA_NAME AS "Schema",
ROUND(SUM(MEMORY_SIZE_IN_TOTAL)/1024/1024) AS "Schema CS Memory (MB)"
FROM M_CS_TABLES AS T JOIN M_SERVICES AS S ON T.HOST = S.HOST AND T.PORT =S.PORT WHERE LOADED <> 'NO'
GROUP BY S.HOST, SERVICE_NAME, SCHEMA_NAME
ORDER BY "Schema CS Memory (MB)" DESC
To get a breakdown by amount of memory consumed by a specific table. This also shows which of its columns are loaded, and the compression ratio that was accomplished. For example, list all tables for schema "HANADB":
SELECT TABLE_NAME as "Table",
round(MEMORY_SIZE_IN_TOTAL/1024/1024) as "MB Used"
from M_CS_TABLES where SCHEMA_NAME = 'SYSTEM’ order by "MB Used" desc
To get a breakdown by columns of a single table, actual size of the data, the "delta changes" and the compression ratio for each of its columns.
select COLUMN_NAME as "Column", LOADED,
round(UNCOMPRESSED_SIZE/1024/1024) as "Uncompressed MB",
round(MEMORY_SIZE_IN_MAIN/1024/1024) as "Main MB",
round(MEMORY_SIZE_IN_DELTA/1024/1024) as "Delta MB",
round(MEMORY_SIZE_IN_TOTAL/1024/1024) as "Total Used MB",
round(COMPRESSION_RATIO_IN_PERCENTAGE/100, 2) as "Compr. Ratio"
from M_CS_COLUMNS where TABLE_NAME = 'Item’
Total Memory Consumption of All Column Tables by Schema:
SELECT SCHEMA_NAME AS "Schema",
round(sum(MEMORY_SIZE_IN_TOTAL) /1024/1024) AS "MB"
FROM M_CS_TABLES GROUP BY SCHEMA_NAME ORDER BY "MB" DESC;
Points on Performance: ( why accessing the data is fast in column store ? )
* Column store databases stores a dictionary of every distinct value that occurs in the column.
* For each distinct value one needs to maintain a list that tells, for which row a specific value occurs
* When we want to get a row/record from these values we need to go through each and every column and find the appropriate match. This is nothing but index inversing.
To get a high-level overview of the amount of memory used for Column Store tables, you can execute the following SQL statement:
SELECT ROUND(SUM(MEMORY_SIZE_IN_TOTAL)/1024/1024) AS "CS Memory (MB)",
ROUND(SUM(MEMORY_SIZE_IN_MAIN)/1024/1024) AS "CS Memory In Main (MB)",
ROUND(SUM(MEMORY_SIZE_IN_DELTA)/1024/1024) AS "CS Memory In Delta(MB)"
FROM M_CS_TABLES WHERE LOADED <> 'NO’
To get a breakdown by host, service, and schema, you can execute the following statement:
SELECT S.HOST AS "Host",
SERVICE_NAME AS "Service",
SCHEMA_NAME AS "Schema",
ROUND(SUM(MEMORY_SIZE_IN_TOTAL)/1024/1024) AS "Schema CS Memory (MB)"
FROM M_CS_TABLES AS T JOIN M_SERVICES AS S ON T.HOST = S.HOST AND T.PORT =S.PORT WHERE LOADED <> 'NO'
GROUP BY S.HOST, SERVICE_NAME, SCHEMA_NAME
ORDER BY "Schema CS Memory (MB)" DESC
To get a breakdown by amount of memory consumed by a specific table. This also shows which of its columns are loaded, and the compression ratio that was accomplished. For example, list all tables for schema "HANADB":
SELECT TABLE_NAME as "Table",
round(MEMORY_SIZE_IN_TOTAL/1024/1024) as "MB Used"
from M_CS_TABLES where SCHEMA_NAME = 'SYSTEM’ order by "MB Used" desc
To get a breakdown by columns of a single table, actual size of the data, the "delta changes" and the compression ratio for each of its columns.
select COLUMN_NAME as "Column", LOADED,
round(UNCOMPRESSED_SIZE/1024/1024) as "Uncompressed MB",
round(MEMORY_SIZE_IN_MAIN/1024/1024) as "Main MB",
round(MEMORY_SIZE_IN_DELTA/1024/1024) as "Delta MB",
round(MEMORY_SIZE_IN_TOTAL/1024/1024) as "Total Used MB",
round(COMPRESSION_RATIO_IN_PERCENTAGE/100, 2) as "Compr. Ratio"
from M_CS_COLUMNS where TABLE_NAME = 'Item’
Total Memory Consumption of All Column Tables by Schema:
SELECT SCHEMA_NAME AS "Schema",
round(sum(MEMORY_SIZE_IN_TOTAL) /1024/1024) AS "MB"
FROM M_CS_TABLES GROUP BY SCHEMA_NAME ORDER BY "MB" DESC;
Points on Performance: ( why accessing the data is fast in column store ? )
* Column store databases stores a dictionary of every distinct value that occurs in the column.
* For each distinct value one needs to maintain a list that tells, for which row a specific value occurs
* When we want to get a row/record from these values we need to go through each and every column and find the appropriate match. This is nothing but index inversing.
Advantages of column store:
- Only affected colums have to be read during the selection process of a query.
- Any of these columns can serve as an index
- Improves read functionality significantly, also improves write functionality
- Highly compressed data
- No real files, virtual files
- Optimizer and Executer – Handles queries and execution plan
- Delta data for fast write
- Asynchronous delta merge
- Consistent view Manager
- Recommended when the tables contain huge volumes of data.
- Used when lot of aggregations need to be done on the tables.
- Supports parallel processing.
The disadvantages are :
- After selection selected rows have to be reconstructed from columns.
- There is no easy way to insert / update.
Note: To enable fast on-the-fly aggregations, ad-hoc reporting, and to benefit from compression mechanisms it is recommended that transaction data is stored in a column-based table.The SAP HANA data-base allows joining row-based tables with column-based tables. However, it is more efficient to join tables that are located in the same row or column store. For example, master data that is frequently joined with transaction data should also be stored in column-based tables.
Topic on - Row Store Table in SAP HANA
Topic on - Convert Row Store to Column Store Table in HANA
Note: To enable fast on-the-fly aggregations, ad-hoc reporting, and to benefit from compression mechanisms it is recommended that transaction data is stored in a column-based table.The SAP HANA data-base allows joining row-based tables with column-based tables. However, it is more efficient to join tables that are located in the same row or column store. For example, master data that is frequently joined with transaction data should also be stored in column-based tables.
Topic on - Row Store Table in SAP HANA
Topic on - Convert Row Store to Column Store Table in HANA
1 comment:
I'm trying to match the total memory size of the particular table ( M_CS_TABLES) with Columns of that table (M_CS_COLUMNS) .
But I can't match the total. Could you advice what is the reason it can't match.
Below is my query :
Select round(Sum(MEMORY_SIZE_IN_TOTAL/1024/1024)) as "Total Used MB"
From M_CS_COLUMNS where Table_Name = <>
and Schema_Name = <>
Select round(Sum(MEMORY_SIZE_IN_TOTAL)/1024/1024) as "Total MB",
From M_CS_TABLES where TABLE_NAME = <>
And SCHEMA_NAME = <>
Post a Comment