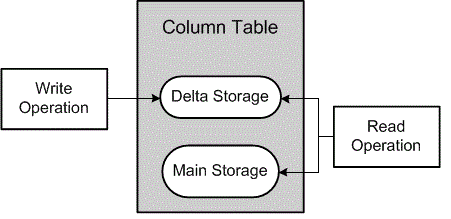
The purpose of the delta merge operation is to move the data from WRITE optimized DELTA memory to READ optimized and Compressed MAIN memory or in simple terms, move the changes collected in the delta storage to the read-optimized main storage.
Delta Merge Operation can be performed by 3 ways.
1> Delta Merge can be done automatically by HANA using Smart Merge technology.
2> Delta Merge can be done manually by using MERGE DETLA of SQL statement.
3> Delta Merge can be done by using HANA studio.
Prerequisites : You should have one of the following privileges:
1> System privilege TABLE ADMIN.
2> SQL object should have UPDATE privilege for the table or the schema in which the table is located.
MERGE DELTA : The MERGE DELTA statement merges the column store table delta storage to the tables main storage.
SQL statement for MERGE DELTA :
1> MERGE DELTA OF '(table_name)' (hard merge)
2> MERGE DELTA OF '(table_name)' WITH PARAMETERS ('FORCED_MERGE' = 'ON') (forced merge)
3> MERGE DELTA OF '(table_name)' WITH PARAMETERS ('MEMORY_MERGE' = 'ON') (memory-only merge)
Manual Delta Merge Operation : You can trigger the delta merge operation for a column table manually by using merge delta operation or from HANA studio.It may be necessary to trigger a merge operation manually , for example:
1> An alert has been issued because a table is exceeding the threshold for the maximum size of delta storage.
2> You need to free up memory. Executing a delta merge operation on tables with large delta storages is one strategy for freeing up memory.
3> The delta storage does not compress data well and it may hold old versions of records that are no longer required for consistent reads.
4> In order to optimize query execution performance of the system and to ensure optimum compression, the system needs to transfer the data from the delta part into the main part.
SMART MERGE Option : When the SMART_MERGE is ON the the HANA database does a smart merge based on merge criteria specified in mergedog section of the indexserver configuration.
Adding a column store table ABC in SMART_MERGE option Using below SQL.
MERGE DELTA OF A WITH PARAMETERS('SMART_MERGE' = 'ON');
Note : Even though the delta merge operation moves data from the delta storage to the main storage but the size of the delta storage will not be zero because of while the
delta merge operation was taking place, records written by open transactions were moved to the new delta storage.
Delta Merge Monitoring :
Delta Merge Operation Monitoring can be done by HANA Studio :
The delta merge operation can take a long time so we can monitor the progress of currently running delta merge operations in the HANA Studio Administration.
Performance ---- Job Progress.
Merge History - merge history can be check by opening the Merge Statistics table on the System Information tab and The SUCCESS column indicates whether or not the merge operation was executed.
Delta Merge Operation Monitoring by using SQL Statement:
we can check the values in M_CS_COLUMNS view for the memory_size_in_total, memory_size_in_main , memory_size_in_delta before and after the delta merge operation to see the difference.
SQL statement to retrieve the top 100 largest delta storages in memory:
SELECT TOP 100 * from M_CS_TABLES ORDER BY MEMORY_SIZE_IN_DELTA DESC.
FAQ : what is Delta Log in Delta Merge ?
The column store creates, its logical redolog entries for all operations executed on the delta storage. This log known as the delta log. The delta merge operation truncates the delta log (ie redo operations).
we can adjust the logging settings for single column tables using below SQL .
ALTER TABLE TABLE_NAME {ENABLE | DISABLE} DELTA LOG;
Note : After enabling, we have to perform a savepoint to be certain that all data is persisted. Also we should perform the data backup because it will not be possible to recover this data.
If logging is disabled, log entries will not be persisted for logging disabled table .the Changes to this table will only be written to the data store and when a savepoint is carried out. This can cause loss of committed transaction should the indexserver terminate. In the case of a termination, you should have to truncate this table and insert all data again.
For a column store table, the logging setting can be seen in the table :