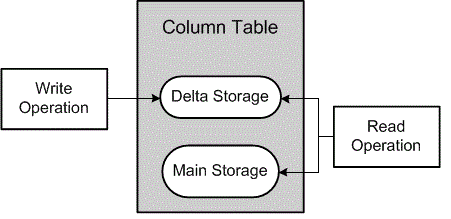
Here , I explained how to check hana database size by using hdbsql & hdbcons utility.
First Login to HANA Database using hdbsql then run the below queries.
1- The number of used blocks in the data volumes
hdbsql SID=> select sum(allocated_page_size) from m_converter_statistics
SUM(ALLOCATED_PAGE_SIZE)
3497635840
2- The license relevant HANA memory usage
select product_usage from m_license
Note : The first metric is useful to compare HANA with other RDBMS, e.g. what is the compression ratio compared to ordinary row-store databases. The second metric is important e.g. for sizing the hardware.
Checking Database Size Using hdbcons Utility -
xxx200132:HDB:sidadm xyz/usr/sap/SID/HDB02/vadbabc> hdbcons 'dvol info'
SAP HANA DB Management Client Console (type '\?' to get help for client commands)
Try to open connection to server process 'hdbindexserver' on system 'ABC', instance '02'
SAP HANA DB Management Server Console (type 'help' to get help for server commands)
Executable: hdbindexserver (PID: 9104)
[OK]
--
DataVolume #0 (xyz/hdb/SID/data/mnt00004/hdb00002/)
size= 16760078336
used= 3464384512
NOTE: We recommend shrinking this DataVolume. Use 'dvol shrink -i 0 -o -v'.
Please use a percentage higher than 110% to avoid long runtime and performance decrease!
[OK]
--
[EXIT]
--
[BYE]
First Login to HANA Database using hdbsql then run the below queries.
1- The number of used blocks in the data volumes
hdbsql SID=> select sum(allocated_page_size) from m_converter_statistics
SUM(ALLOCATED_PAGE_SIZE)
3497635840
2- The license relevant HANA memory usage
select product_usage from m_license
Note : The first metric is useful to compare HANA with other RDBMS, e.g. what is the compression ratio compared to ordinary row-store databases. The second metric is important e.g. for sizing the hardware.
Checking Database Size Using hdbcons Utility -
xxx200132:HDB:sidadm xyz/usr/sap/SID/HDB02/vadbabc> hdbcons 'dvol info'
SAP HANA DB Management Client Console (type '\?' to get help for client commands)
Try to open connection to server process 'hdbindexserver' on system 'ABC', instance '02'
SAP HANA DB Management Server Console (type 'help' to get help for server commands)
Executable: hdbindexserver (PID: 9104)
[OK]
--
DataVolume #0 (xyz/hdb/SID/data/mnt00004/hdb00002/)
size= 16760078336
used= 3464384512
NOTE: We recommend shrinking this DataVolume. Use 'dvol shrink -i 0 -o
Please use a percentage higher than 110% to avoid long runtime and performance decrease!
[OK]
--
[EXIT]
--
[BYE]